The Separation Tax: When You Split Data Between Your Relational And Vector DB

As my agentic applications grew more complex, I started uncovering problems that weren’t visible when everything was stateless. At first, while I was proving out small tools (single-shot prompts, temporary context, no persistence), things were simple. But once I layered in state—then agents that manage state and use RAG to retrieve context dynamically—the architecture itself became part of the problem space.
In a previous post, I argued that agentic applications need deterministic foundations.
The short version: if the top of your stack is intentionally non-deterministic (creative, adaptive AI), the foundation has to be rock-solid.
However, non-determinism isn’t the only cost you pay when you separate vector and relational data in RAG applications. You eventually encounter a separation tax on correctness, simplicity, performance, and observability.
The Cost of Separation
When I first added RAG, I reached for a vector database for embeddings and kept CockroachDB for relational data. On paper, it looked fine:
structured metadata in CRDB,
embeddings in a vector store,
application/agents orchestrating both.
In practice, separation shows up as four recurring costs:
1) Correctness drift (not just dual-writes)
Yes, dual-writes can leave embeddings stale, but another issue is policy and retrieval diverging:
Permissions/region/PII flags live in relational tables, while retrieval happens elsewhere.
You end up filtering after retrieval, which means the model may see candidates it shouldn’t or reason from an incomplete snapshot.
2) Complexity
Two systems = two schemas, two backups, two monitoring planes, two incident playbooks.
You need glue for sync, retries, and idempotency.
Every feature that touches knowledge now crosses a boundary and doubles in complexity.
3) Performance taxes you can’t index away
More hops: app → vector DB → app → relational DB (then post-filter).
Bigger candidate sets: vague prefiltering in the vector tier, precise constraints later.
Worse tail latency: small percentiles dominate user perception, and each hop compounds it.
4) Observability gaps
You can’t EXPLAIN an end-to-end plan across two engines.
You see half-plans and infer the rest.
Fingerprinting and regression tracking break across the boundary.
Once you move out of POC territory, these can become serious headaches. As with any problem, there are many approaches you could take. In my case, I reached for simplicity.
With a relational database that supports Vector types, I’m able to simplify my designs so retrieval, policy, and state coexist to coordinate.
From Separation to Co-Location (What We’ll Build Next)
In my real applications, I was not using the Reporter. But I’ll stick with that as an example, just to keep the context.
Imagine you’re a consultant for a company that specializes in tuning databases. We could update the Reporter App such that it has a feature to perform similarity searches. This would enable you to explore actions and outcomes taken on systems similar to one you’re tuning. But your company may have clients who only want to share data with consultants named on the project. So we’ll need to account for that as well.
For this update, we want to design the system such that:
Embeddings and metadata live together in a relational database,
Guardrails (PII, region, role) are enforced inside the retrieval query,
Writes are atomic (report text + embedding update in a single transaction),
And observability (e.g.,
EXPLAIN ANALYZE) applies to the whole plan.
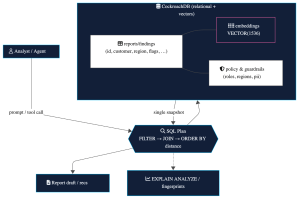
In the next section, we’ll walk through a minimal schema and the core query patterns that make this work:
filter → (join) → order by vector distance, all under one serializable snapshot.
It’s a simplified use case, but I think you’ll find the pattern useful in broader scenarios.
The Co-Located Reporter (Concept)
The Reporter already:
ingests cluster metrics via API,
creates structured records (findings, actions, comments) via MCP tools,
persists everything in CockroachDB,
and keeps a human reviewer in the loop.
Now we add memory:
1) Embed past reports/findings so the agent can find similar situations.
2) Keep permissions, region/compliance flags, and PII markers alongside those embeddings.
3) Query for “similar cases I’m allowed to see” in one SQL plan.
Minimal Schema (relational + vector, with guardrails)
CREATE TABLE reports (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
customer_id UUID NOT NULL,
title STRING,
created_by STRING,
created_at TIMESTAMP NOT NULL DEFAULT now(),
pii_flag BOOL NOT NULL DEFAULT FALSE,
region STRING, -- e.g., 'US', 'EU'
crdb_version STRING,
severity STRING, -- e.g., 'low'|'moderate'|'high'
report_text STRING,
embedding VECTOR(1536) -- co-located semantic representation
);
-- Per-user access control for consultants/analysts
CREATE TABLE user_access (
user_id UUID NOT NULL,
report_id UUID NOT NULL,
PRIMARY KEY (user_id, report_id)
);
-- Optional content flags for finer guardrails
CREATE TABLE content_flags (
report_id UUID NOT NULL,
flag STRING NOT NULL, -- e.g., 'pii', 'restricted_customer'
PRIMARY KEY (report_id, flag)
);Observability note: because this all lives in one database, EXPLAIN ANALYZE and query fingerprints apply to the whole retrieval+policy plan.
One Query: Similar Reports I’m Allowed To See
WITH authorized AS (
SELECT report_id AS id
FROM user_access
WHERE user_id = $1
)
SELECT r.id,
r.title,
r.customer_id,
r.region,
r.severity,
vector_distance(r.embedding, $2) AS score
FROM reports AS r
JOIN authorized a USING (id)
WHERE r.pii_flag = FALSE
AND r.region = $3 -- region boundary (e.g., match analyst region)
AND r.severity IN ('moderate','high')
ORDER BY score
LIMIT 10;This is retrieval + guardrails + business filters in a single serializable snapshot:
If a report is flagged PII or out-of-region, it never becomes a candidate.
If access is revoked, the join eliminates it before scoring.
No post-filter “oops” moments.
The Write Path: Atomic, Not Eventual
When the agent (or human) updates a report’s text and re-embeds it, both changes commit or roll back together:
BEGIN;
UPDATE reports
SET report_text=$1,
embedding=$2,
severity=$3
WHERE id=$4
COMMIT;
One transaction = one truth.
Performance: Filter → (Join) → Order by Distance
Start with exact search + strong filters:
Constrain by region, severity, customer, time windows.
Project only needed columns.
Order by vector distance last (on a small candidate set).
As data grows, add ANN indexing; until then, filters + exact distance are fast and fully accurate.
Why Co-Location Changes the Shape of RAG
Correctness: retrieval and policy run under the same plan/snapshot.
Simplicity: one schema, one backup, one monitoring plane.
Performance: prefilter with indexes; compute distance on fewer rows.
Observability:
EXPLAIN ANALYZEshows the whole picture, not just half.
In other words, RAG becomes a relational capability the Reporter can rely on deterministically.
When semantics meet relations under ACID, retrieval becomes a bounded act of reasoning as opposed to a simple recall. Co-locating vectors with metadata lets you express hypotheses as predicates and distances in the same query plan—what should be visible, which era matters, which regions and roles apply, how to weigh similarity against severity—and settle it with a single, auditable transaction.
The result isn’t just “a model said so,” but “the system proved it under one snapshot.” That’s the qualitative shift: rather than just fetching context, the agent reasons over state and the database provides the guardrails, evidence, and durability that make those judgments more trustworthy.